Oracle 11g: Incremental Global Statistics On Partitioned Tables
Previously I blogged about the new and improved DBMS_STATS.AUTO_SAMPLE_SIZE used to calculate NDV in Oracle 11g and now I wanted to touch on another new feature of DBMS_STATS in 11g: Incremental Global Statistics On Partitioned Tables.
Before Incremental Global Stats (Two-Pass Method)
When DBMS_STATS.GATHER_TABLE_STATS collects statistics on a partitioned table, generally it does so at the partition and table (global) level (the default behavior can be modified by changing the GRANULARITY parameter). This is done in two steps. First, partition level stats are gathered by scanning the partition(s) that have stale or empty stats, then a full table scan is executed to gather the global statistics. As more partitions are added to a given table, the longer the execution time for GATHER_TABLE_STATS, due to the full table scan requited for global stats.
Using Incremental Global Stats (Synopsis-Based Method)
Incremental Global Stats works by collecting stats on partitions and storing a synopsis which is the statistics metadata for that partition and the columns for that partition. This synopsis is stored in the SYSAUX tablespace, but is quite small (only a few kilobytes). Global stats are then created not by reading the entire table, but by aggregating the synopses from each partition. Incremental Global Stats, in conjunction with the new 11g DBMS_STATS.AUTO_SAMPLE_SIZE, yield a significant reduction in the time to collect statistics and produce near perfect accuracy.
Turning On Incremental Global Stats
Incremental Global Stats can only be used for partitioned tables and is activated by this command:
SQL> exec DBMS_STATS.SET_TABLE_PREFS(user,'FOO','INCREMENTAL','TRUE')
-- To see the value for INCREMENTAL for a given table:
SQL> select dbms_stats.get_prefs('INCREMENTAL', tabname=>'FOO') from dual;
DBMS_STATS.GET_PREFS('INCREMENTAL',TABNAME=>'FOO')
--------------------------------------------------
TRUE
You may also use any of the other DBMS_STATS.SET_*_PREFS as well.
A Real-World Example
To demonstrate the benefit of Incremental Global Statistics, I created a range partitioned table consisting of 60 range partitions. The target table starts empty and one million (1,000,000) rows are inserted into a single partition of the table and then statistics are gathered. This is done 60 times, simulating loading 60 one day partitions (one at a time) emulating a daily ETL/ELT process over 60 days.
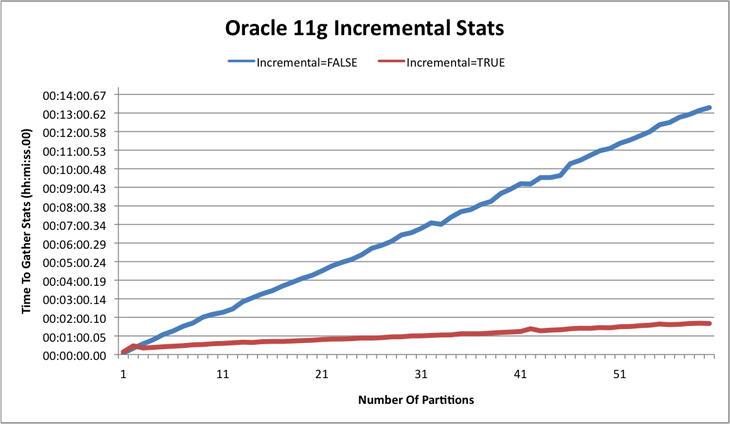
| Partitions | Incremental=FALSE | Incremental=TRUE |
|---|---|---|
| 1 | 00:00:20.36 | 00:00:21.14 |
| 10 | 00:02:27.25 | 00:00:37.76 |
| 20 | 00:04:46.23 | 00:00:49.83 |
| 30 | 00:07:05.47 | 00:01:01.80 |
| 40 | 00:09:11.09 | 00:01:23.33 |
| 50 | 00:11:33.18 | 00:01:30.40 |
| 60 | 00:13:18.15 | 00:01:40.28 |
| Cumulative Elapsed Time | 06:42:21.20 | 01:00:53.80 |
As you can see from the chart and the table, without Incremental Global Stats the time to gather stats increases pretty much linearly with the number of partitions, but with Incremental Global Stats the elapse time only slightly increases. The big difference is in the cumulative elapsed time: It takes 6 hours 42 minutes without Incremental Global Stats, but only 1 hour with. Quite a significant savings over time!
Revisiting The Math
For this experiment the time to gather stats without Incremental Global Stats is: (time to scan & gather for 1 partition) + (time to scan and gather for entire table) When Incremental Global Stats is used the time to gather stats is: (time to scan & gather for 1 partition) + (time to aggregate all synopses)
The Diff Test
I exported the stats into a stats table and then ran the diff to compare the two runs. This will show us how comparable the two methods of stats gathering are.
SQL> set long 500000 longchunksize 500000
SQL> select report, maxdiffpct from
table(dbms_stats.diff_table_stats_in_stattab(user,'CATALOG_SALES','STATS_DEFAULT','STATS_INC'));
REPORT
------------------------------------------------------------------------------------
MAXDIFFPCT
----------
###############################################################################
STATISTICS DIFFERENCE REPORT FOR:
.................................
TABLE : CATALOG_SALES
OWNER : TPCDS
SOURCE A : User statistics table STATS_DEFAULT
: Statid :
: Owner : TPCDS
SOURCE B : User statistics table STATS_INC
: Statid :
: Owner : TPCDS
PCTTHRESHOLD : 10
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
NO DIFFERENCE IN TABLE / (SUB)PARTITION STATISTICS
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
COLUMN STATISTICS DIFFERENCE:
.............................
COLUMN_NAME SRC NDV DENSITY HIST NULLS LEN MIN MAX SAMPSIZ
...............................................................................
CS_BILL_ADDR_SK A 1001152 .000000998 NO 148640 5 C102 C402 5.9E+07
B 1001176 .000000998 NO 148613 5 C102 C402 5.9E+07
CS_BILL_CDEMO_S A 1868160 .000000535 NO 148646 6 C102 C4025 5.9E+07
B 1878320 .000000532 NO 148753 6 C102 C4025 5.9E+07
CS_BILL_CUSTOME A 1942528 .000000514 NO 148104 6 C102 C403 5.9E+07
B 1949464 .000000512 NO 148192 6 C102 C403 5.9E+07
CS_BILL_HDEMO_S A 7200 .000138888 NO 148227 4 C102 C249 5.9E+07
B 7200 .000138888 NO 148250 4 C102 C249 5.9E+07
CS_CALL_CENTER_ A 30 .033333333 NO 148310 3 C102 C11F 5.9E+07
B 30 .033333333 NO 148272 3 C102 C11F 5.9E+07
CS_CATALOG_PAGE A 11092 .000090155 NO 148111 5 C102 C3023 5.9E+07
B 11092 .000090155 NO 148154 5 C102 C3023 5.9E+07
CS_EXT_LIST_PRI A 1133824 .000000881 NO 148461 6 C102 C3036 5.9E+07
B 1131680 .000000883 NO 148368 6 C102 C3036 5.9E+07
CS_EXT_WHOLESAL A 394880 .000002532 NO 148842 5 C102 C302 5.9E+07
B 394880 .000002532 NO 148772 5 C102 C302 5.9E+07
CS_ITEM_SK A 205888 .000004857 NO 0 5 C102 C3152 5.9E+07
B 205408 .000004868 NO 0 5 C102 C3152 5.9E+07
CS_LIST_PRICE A 29896 .000033449 NO 148438 5 C102 C204 5.9E+07
B 29896 .000033449 NO 148458 5 C102 C204 5.9E+07
CS_ORDER_NUMBER A 7151104 .000000139 NO 0 6 C102 C4102 5.9E+07
B 7122072 .000000140 NO 0 6 C102 C4102 5.9E+07
CS_PROMO_SK A 1000 .001 NO 148617 4 C102 C20B 5.9E+07
B 1000 .001 NO 148693 4 C102 C20B 5.9E+07
CS_QUANTITY A 100 .01 NO 148737 3 C102 C202 5.9E+07
B 100 .01 NO 148751 3 C102 C202 5.9E+07
CS_SHIP_ADDR_SK A 1001088 .000000998 NO 148150 5 C102 C402 5.9E+07
B 1001152 .000000998 NO 148235 5 C102 C402 5.9E+07
CS_SHIP_CDEMO_S A 1870592 .000000534 NO 148918 6 C102 C4025 5.9E+07
B 1878272 .000000532 NO 148862 6 C102 C4025 5.9E+07
CS_SHIP_CUSTOME A 1938816 .000000515 NO 148300 6 C102 C403 5.9E+07
B 1948928 .000000513 NO 148309 6 C102 C403 5.9E+07
CS_SHIP_DATE_SK A 1884 .000530785 NO 148674 6 C4032 C4032 5.9E+07
B 1884 .000530785 NO 148608 6 C4032 C4032 5.9E+07
CS_SHIP_HDEMO_S A 7200 .000138888 NO 148172 4 C102 C249 5.9E+07
B 7200 .000138888 NO 148161 4 C102 C249 5.9E+07
CS_SHIP_MODE_SK A 20 .05 NO 148437 3 C102 C115 5.9E+07
B 20 .05 NO 148486 3 C102 C115 5.9E+07
CS_SOLD_DATE_SK A 1595 .000626959 NO 0 6 C4032 C4032 5.9E+07
B 1587 .000630119 NO 0 6 C4032 C4032 5.9E+07
CS_WAREHOUSE_SK A 15 .066666666 NO 148651 3 C102 C110 5.9E+07
B 15 .066666666 NO 148620 3 C102 C110 5.9E+07
CS_WHOLESALE_CO A 9901 .000100999 NO 149054 4 C102 C202 5.9E+07
B 9901 .000100999 NO 149099 4 C102 C202 5.9E+07
The stats diff shows that for many columns the NDV is identical and the others are statistically equivalent (close enough to be the same). I will certainly be adding this feature to my “conviction must use list” for Oracle 11g.
Further Reading
If you are interested in the bits and bytes of how the synopsis-based method works, I would suggest you read the whitepaper, Efficient and Scalable Statistics Gathering for Large Databases in Oracle 11g that was presented on this topic at SIGMOD 2008.