The Core Performance Fundamentals Of Oracle Data Warehousing – Balanced Hardware Configuration
[back to Introduction]
If you want to build a house that will stand the test of time, you need to build on a solid foundation. The same goes for architecting computer systems that run databases. If the underlying hardware is not sized appropriately it will likely lead to people blaming software. All too often I see data warehouse systems that are poorly architected for the given workload requirements. I frequently tell people, “you can’t squeeze blood from a turnip”, meaning if the hardware resources are not there for the software to use, how can you expect the software to scale?
Undersizing data warehouse systems has become an epidemic with open platforms - platforms that let you run on any brand and configuration of hardware. This problem has been magnified over time as the size of databases have grown significantly, and generally outpacing the experience of those managing them. This has caused the “big three” database vendors to come up with suggested or recommended hardware configurations for their database platforms:
- Oracle: Optimized Warehouse Initiative
- Microsoft: SQL Server Fast Track Data Warehouse
- IBM: Balanced Configuration Unit (BCU)
Simply put, the reasoning behind those initiatives was to help customers architect systems that are well balanced and sized appropriately for the size of their data warehouse.
Balanced Hardware Configurations
The foundation for a well performing data warehouse (or any system for that matter) is the hardware that it runs on. There are three main hardware resources to consider when sizing your data warehouse hardware. Those are:
- Number of CPUs
- Number of storage devices (HDDs or SSDs)
- I/O bandwidth between CPUs and storage devices
NB: I’ve purposely left off memory (RAM) as most systems are pretty well sized at 2GB or 4GB per CPU core these days.
A balanced system has the following characteristics:
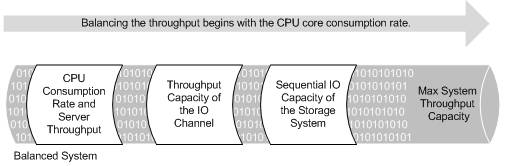
As you can see, each of the three components are sized proportionally to each other. This allows for the max system throughput capacity as no single resource will become the bottleneck before any other. This was one of the critical design decisions that went into the Oracle Database Machine.
Most DBAs and System Admins know what the disk capacity numbers are for their systems, but when it comes to I/O bandwidth or scan rates, most are unaware of what the system is capable of in theory, let alone in practice. Perhaps I/O bandwidth utilization should be included in the system metrics that are collected for your databases. You do collect system metrics, right?
There are several “exchanges” that data must flow through from storage devices to host CPUs, many of which could become bottlenecks. Those include:
- Back-end Fibre Channel loops (the fibre between the drive shelves and the storage array server processor)
- Front-end Fibre Channel ports
- Storage array server processors (SP)
- Host HBAs
One should understand the throughput capacity of each of these components to ensure that one (or more) of them do not restrict the flow of data to the CPUs prematurely.
Unbalanced Hardware Configurations
All too frequently systems are not architected as balanced systems and the system ends up being constrained in one of the following three scenarios:
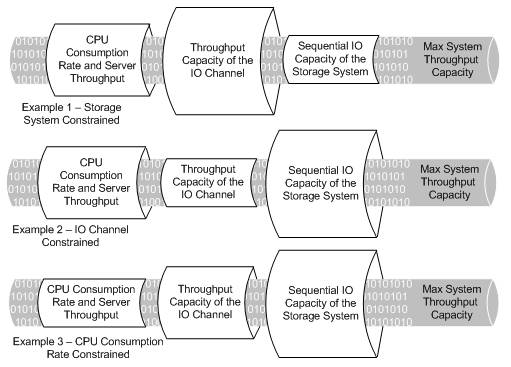
From the production systems that I have seen, the main deficiency is in I/O bandwidth (both I/O Channel and HDD). I believe there are several reasons for this. First, too many companies capacity plan for their data warehouse based on the size the data occupies on disk alone. That is, they purchase the number of HDDs for the system based on the drive capacity, not on the I/O bandwidth requirement. Think of it like this: If you were to purchase 2 TB of mirrored disk capacity (4 TB total) would you rather purchase 28 x 146 GB drives or 14 x 300 GB drives (or even 4 x 1 TB drives)? You may ask: Well, what is the difference (other than price); in each case you have the same net capacity, correct? Indeed, both configurations do have the same capacity, but I/O bandwidth (how fast you can read data off the HDDs) is proportional to the number of HDDs, not the capacity. Thus it should be slightly obvious then that 28 HDDs can deliver 2X the disk I/O bandwidth that 14 HDDs can. This means that it will take 2X as long to read the same amount of data off of 14 HDDs as 28 HDDs.
Unfortunately what tends to happen is that the bean counter types will see only two things:
- The disk capacity (space) you want to purchase (or the capacity that is required)
- The price per MB/GB/TB
This is where someone worthy of the the title systems architect needs to stand up and explain the concept of I/O bandwidth and the impact it has on data warehouse performance (your systems architect does know this, correct?). This is generally a difficult discussion because I/O bandwidth is not a line item on a purchase order, it is a derived metric that requires both thought and engineering (which means someone had to do some thinking about the requirements for this system!).
Summary
When sizing the hardware for your data warehouse consider your workload and understand following (and calculate numbers for them!):
- What rate (in MB/GB per second) can the CPUs consume data?
- What rate can storage devices produce data (scan rate)?
- What rate can the data be delivered from the storage array(s) to the host HBAs?
If you are unable to answer these questions in theory then you need to sit down and do some calculations. Then you need to use some micro benchmarks (like Oracle ORION) and prove out those calculations. This will give you the “speed limit” and an metric by which you can measure your database workload against. All computer systems much obey the laws of physics! There is no way around that.
Additional Readings
Kevin Closson has several good blog posts on related topics including:
- SAN Admins: Please Give Me As Much Capacity From As Few Spindles As Possible!
- Hard Drives Are Arcane Technology. So Why Can’t I Realize Their Full Bandwidth Potential?
as well as numerous others.
Oracle Documentation References: